# 哈希表
哈希表(Hash Table,也叫散列表),是根据关键码值 (Key-Value) 而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。哈希表的实现主要需要解决两个问题,哈希函数和哈希冲突。
# 哈希函数
# 哈希冲突
# HashMap
简述一下Java中的HashMap的实现原理
HashMap的底层就是数组加上链表的结构实现的。结构如下图:
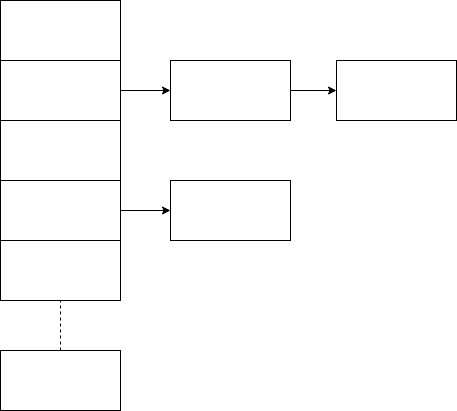
数组用来存放元素位置,链表用来解决哈希冲突。
当需要往HashMap中添加对象时,需要先计算key的hashCode,然后hashCode计算出元素应该放在数组的哪个位置。找到该位置后,判断该位置上是否已经存在键值对,如果已存在就覆盖,如果不存在就直接放到该位置。链表的存在是为了解决不同的key出现了Hash冲突的问题。一般元素会放到链表的头,这样做会减少操作。
HashMap有一个扩容因子0.75,当元素数量大于数组长度乘以扩容因子时,会触发扩容操作。扩容时,将数组长度变为原来2倍,然后将元素重新计算hashCode放到相应的位置。
往HashMap中put元素的时候,先根据key计算hashCode,然后找到了数组中的对应位置。那么,是如何根据hashCode找到在数组中的具体位置呢?采用什么算法?
底层数组的初始长度是多少?为什么会设计成这个数呢?
底层数组的默认长度是16。每次扩容都乘以2,都保证长度length是2的n次幂。原因就是这样可以使用位运算来加快计算在数组中的位置。
扩容因子0.75,那么什么时候会触发扩容呢?是数组中元素占用位置的数量超过扩容因子时会触发还是HashMap的总元素数量超过扩容因子时会触发?
HashMap中元素总个数达到阈值时就会扩容。
为什么扩容的时候要重新计算hashCode呢?直接从旧的数组中移到新的数组中移到新的数组响应的位置不可以吗?
扩容的时候是需要重新计算hash的,并且重新放置元素。但是并不可以从旧的数组直接移到新的数组响应的位置。因为虽然key的hashCode不会变,但是数组的长度发生了变化,那么根据hashCode计算数组位置时,得出的索引值也肯定是不同的。如果直接平移过来,会直接导致扩容前添加到HashMap中的数据无法被
get()到。因为数组中的索引变化了,所以无法找到。HashMap是数据结构中哈希表的一个具体实现,还有哪些哈希表的其它实现方式?